Proto is a high-level programming language for designing DNA, RNA, and protein sequences. The required properties of a sequence are expressed as constraints; generators propose candidate sequences and optimizers search for candidates that satisfy them.
Biological sequence design is typically multi-objective: a single sequence must meet several requirements at once. A designed protein may need to fold to a target structure, bind a target, express in a host organism, and remain soluble. A coding sequence may need a controlled GC content, codon usage suited to its host, no long homopolymer runs, and the absence of specified restriction sites. Proto represents each requirement as a separate constraint and optimizes against the full set rather than a single objective.A design is specified declaratively. The sequence regions to be designed are defined as segments; a generator is assigned to each region to propose candidates; constraints score how well each candidate meets a requirement; and one or more optimizers search sequence space to minimize the combined score.
python
from proto_language.core import Segment, Construct, Constraint, Programfrom proto_language.generator import RandomNucleotideGenerator, RandomNucleotideGeneratorConfigfrom proto_language.optimizer import MCMCOptimizer, MCMCOptimizerConfigfrom proto_language.constraint import gc_content_constraint, max_homopolymer_constraintfrom proto_tools.transforms.masking import MaskingStrategy# Define a 200bp DNA sequence to optimizedna = Segment(length=200, sequence_type="dna")construct = Construct(segments=[dna])# Generator: random point mutations to explore sequence spacegen = RandomNucleotideGenerator(RandomNucleotideGeneratorConfig(masking_strategy=MaskingStrategy(num_mutations=3)))gen.assign(dna)# Constraints: what the sequence must satisfyconstraints = [ Constraint(inputs=[dna], function=gc_content_constraint, function_config={"min_gc": 45, "max_gc": 55}, weight=1.0), Constraint(inputs=[dna], function=max_homopolymer_constraint, function_config={"max_length": 5}, threshold=0.0),]# Optimize with MCMCoptimizer = MCMCOptimizer( constructs=[construct], generators=[gen], constraints=constraints, config=MCMCOptimizerConfig(num_steps=500, num_results=5),)program = Program(optimizers=[optimizer], num_results=5)program.run()# Results: 5 optimized sequences ranked by qualityfor seq in construct.joined_sequences: print(seq.sequence)
Segments are contiguous sequence regions to be designed; they are grouped into Constructs. A segment is initialized either from a target length or from an existing sequence.
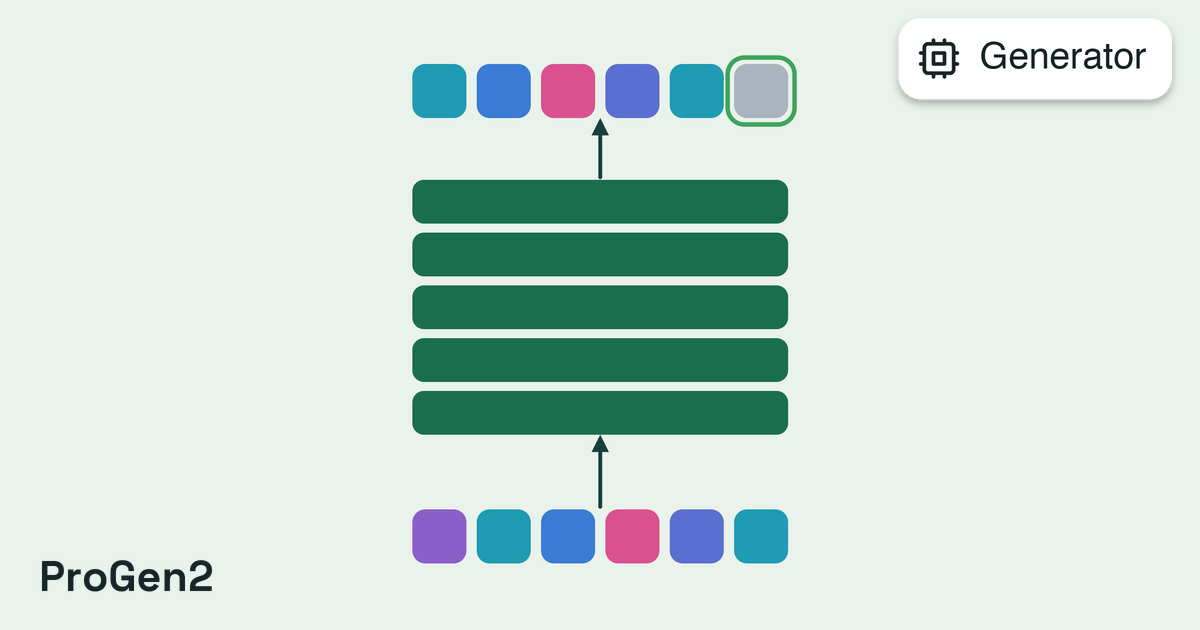
A generator is assigned to a segment and proposes new sequences on each iteration. Generators range from random mutation to protein language models such as ESM2, ESM3, and ProteinMPNN.
A constraint scores how well each proposal meets a requirement, from 0.0 (perfect) to 1.0 (worst). It uses either weight for soft scoring or threshold for hard pass/fail filtering.
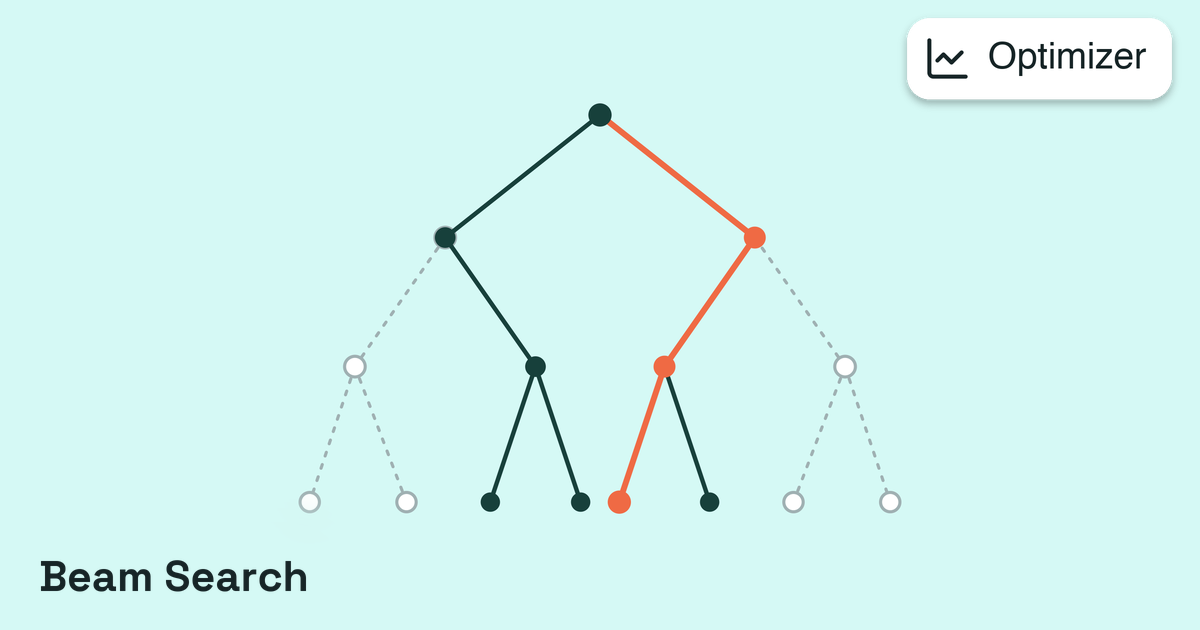
An optimizer searches sequence space to minimize the total constraint score. A Program chains several optimizers into a multi-stage pipeline, for example broad exploration followed by fine-tuning.
python
program = Program(optimizers=[optimizer], num_results=5)program.run()results = construct.joined_sequences # Ranked by quality
Proteins can be designed for predicted structural properties. ESM2 or ProteinMPNN generate proposals, which are scored by ESMFold or Boltz2 for folding confidence, by TM-score for structural similarity, and by additional quality metrics.
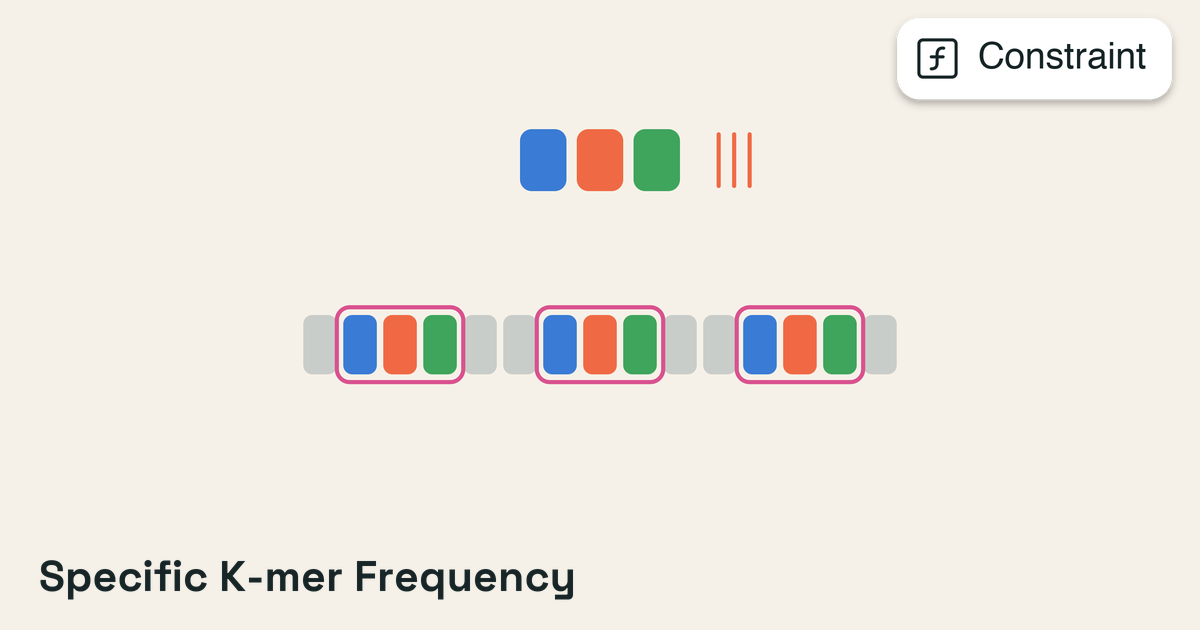
DNA sequences can be optimized for synthesis and expression: GC content, homopolymer runs, restriction sites, and promoter strength are controlled simultaneously.
RNA sequences can be designed for target secondary structures, splice-site properties, or regulatory motifs, combining sequence-level constraints with structure predictions.
Sequences are specified by the properties they must satisfy rather than by a search procedure. Constraints define the requirements; the optimizer performs the search.
Composable Components
Generators, constraints, and optimizers combine freely. Multi-stage pipelines chain broad exploration with targeted refinement.
Integrated ML Models
Built-in support for protein language models, structure predictors, inverse-folding models, and genomic deep-learning models.
Bioinformatics Tools
Tools for structure prediction, sequence search, motif analysis, splicing prediction, and annotation are callable as constraints.
Multi-Objective Optimization
Competing requirements are balanced through weighted scoring and hard threshold filters across any number of constraints.
CPU and GPU
Lightweight generators and constraints run on CPU; structure prediction, language models, and genomic deep learning run on GPU when available.