Generators propose candidate sequences during optimization. Where constraints define the requirements and optimizers orchestrate the search, generators determine where new candidate sequences come from.Every optimization step begins with generators proposing candidates. A generator takes the current sequences in a Segment, applies its strategy (random mutation, protein language model, structure-conditioned design), and fills the proposal_sequences pool for the optimizer to evaluate.
Proto organizes generators by how they produce sequences. The three most common categories are below; a fourth, gradient-based generation (PositionWeightGenerator), produces differentiable position weights for the Gradient optimizer. Each category makes different trade-offs between speed, biological realism, and required prior knowledge.
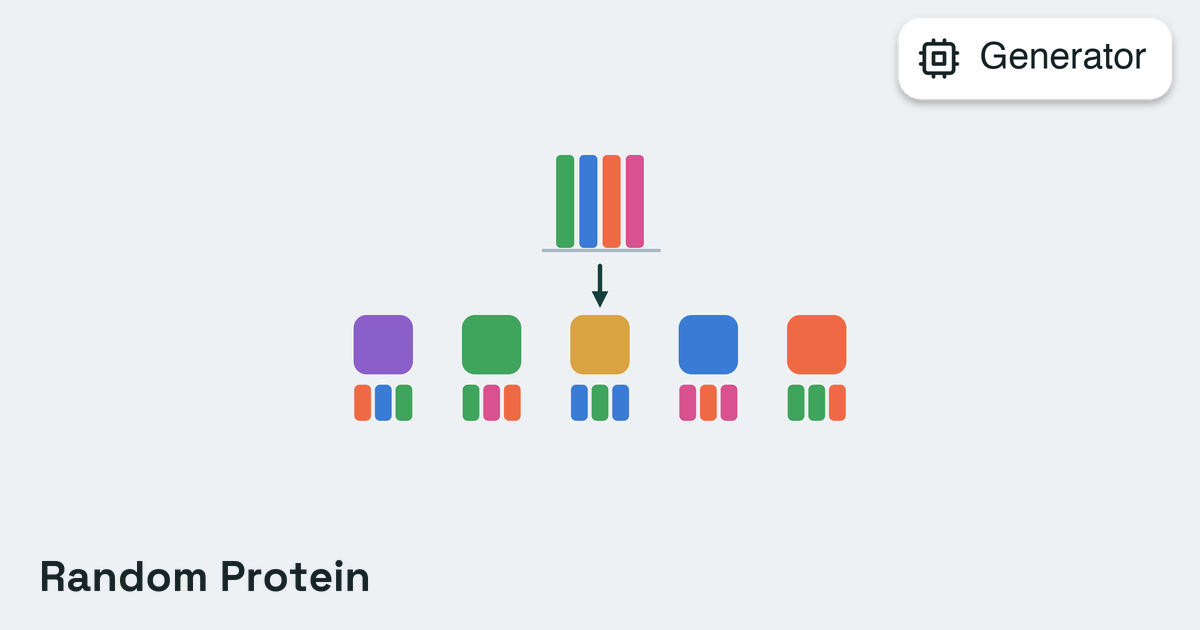
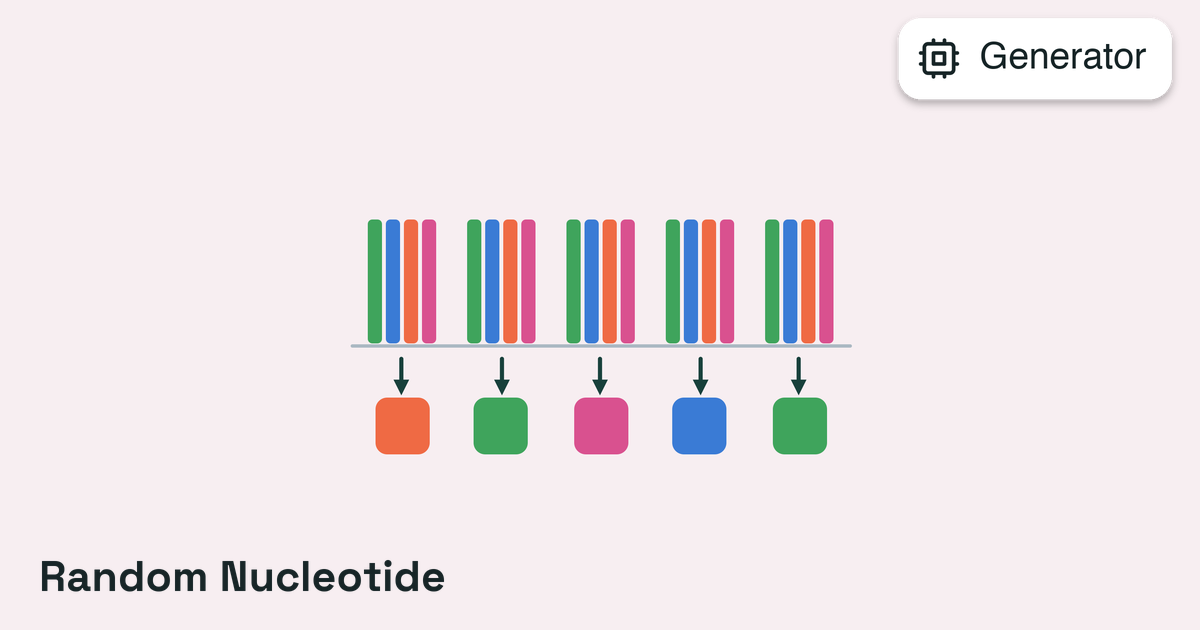
Mutation
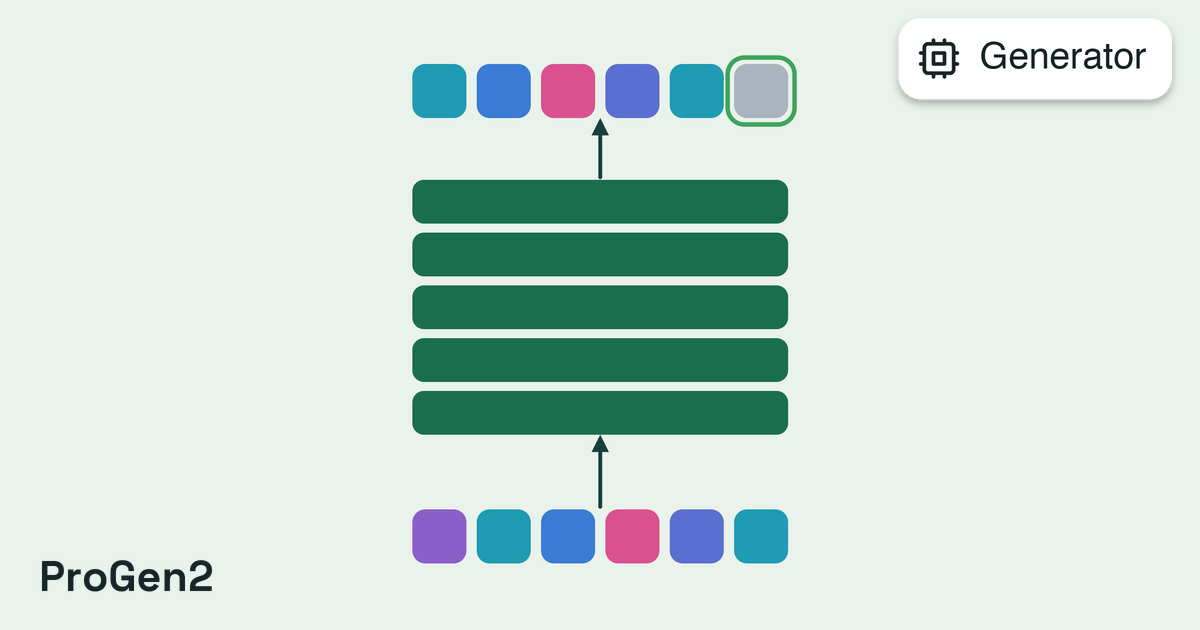
Autoregressive
Inverse Folding
Refine existing sequences by modifying selected positions.Mutation generators start from an existing sequence and introduce changes, either uniformly random or guided by a protein language model’s uncertainty estimates. Most require a starting sequence (ESM2Generator, for example, raises if the segment has none); the random generators (RandomProteinGenerator, RandomNucleotideGenerator) are the exception and initialize one automatically when none is provided.When to use: A starting sequence is available and the goal is to refine it. This is the most common category for iterative optimization.
See the Generator Reference for all available mutation generators and their configuration options.
Generate sequences from scratch, token by token (left-to-right).Autoregressive generators use large language models trained on biological sequences to generate entirely new sequences. They don’t need a starting sequence; they create one from a prompt or from nothing.When to use: Novel sequences are needed (especially long DNA), or the goal is to sample from the model’s learned distribution over natural sequences.
Autoregressive generators overwrite any existing sequences in the segment. If the segment already has input sequences, they will be replaced.
See the Generator Reference for all available autoregressive generators and their configuration options.
Design sequences that fold into a target 3D structure.Inverse folding generators solve the inverse protein design problem: given a desired backbone structure (as a PDB file), predict the amino acid sequence most likely to fold into that shape. They don’t need a starting sequence; unknown positions are initialized as X.When to use: A target protein structure (from experiment or computational design) is available, and the goal is to find sequences that fold into it.
In multi-segment constructs, different generators can be assigned to different segments. Each generator independently proposes candidates for its assigned segment:
python
from proto_language.core import Segment, Constructfrom proto_language.optimizer import MCMCOptimizer, MCMCOptimizerConfig# Two segments with different generation strategiespromoter = Segment(length=200, sequence_type="dna", label="promoter")coding_seq = Segment(length=300, sequence_type="dna", label="cds")construct = Construct([promoter, coding_seq])# Assign different generators to each segmentgen_promoter = RandomNucleotideGenerator( RandomNucleotideGeneratorConfig(masking_strategy=MaskingStrategy(num_mutations=20)))gen_cds = RandomNucleotideGenerator( RandomNucleotideGeneratorConfig(masking_strategy=MaskingStrategy(num_mutations=6)))gen_promoter.assign(promoter)gen_cds.assign(coding_seq)optimizer = MCMCOptimizer( constructs=[construct], generators=[gen_promoter, gen_cds], constraints=[...], config=MCMCOptimizerConfig(num_steps=500, num_results=5, proposals_per_result=10),)
Use different mutation counts for different segments. Conserved regions (like coding sequences) benefit from fewer mutations per step, while exploratory regions (like promoters) can tolerate more.
GPU generators process multiple proposal sequences per forward pass. The batch_size config parameter controls how many sequences are sent to the GPU at once. All generators default to batch_size=1 (sequential processing); increase it to enable batching.The framework splits the full set of proposals into chunks of batch_size and processes each chunk on the GPU. For example, if the optimizer requests 50 proposals and batch_size=16, the generator runs 4 forward passes (16 + 16 + 16 + 2).
If GPU out-of-memory (OOM) errors occur, reduce the generator’s batch_size in its config. This is especially common with long sequences or large models. See the Generator Reference for per-generator configuration details and available parameters.