License: ProGen2 is open source and free for academic and commercial use under a BSD-3-Clause license. Please refer to the license for full terms.
This generator is open source. Any third-party models, product names, or trademarks referenced are the property of their respective owners, and Proto is not affiliated with them.
API Reference
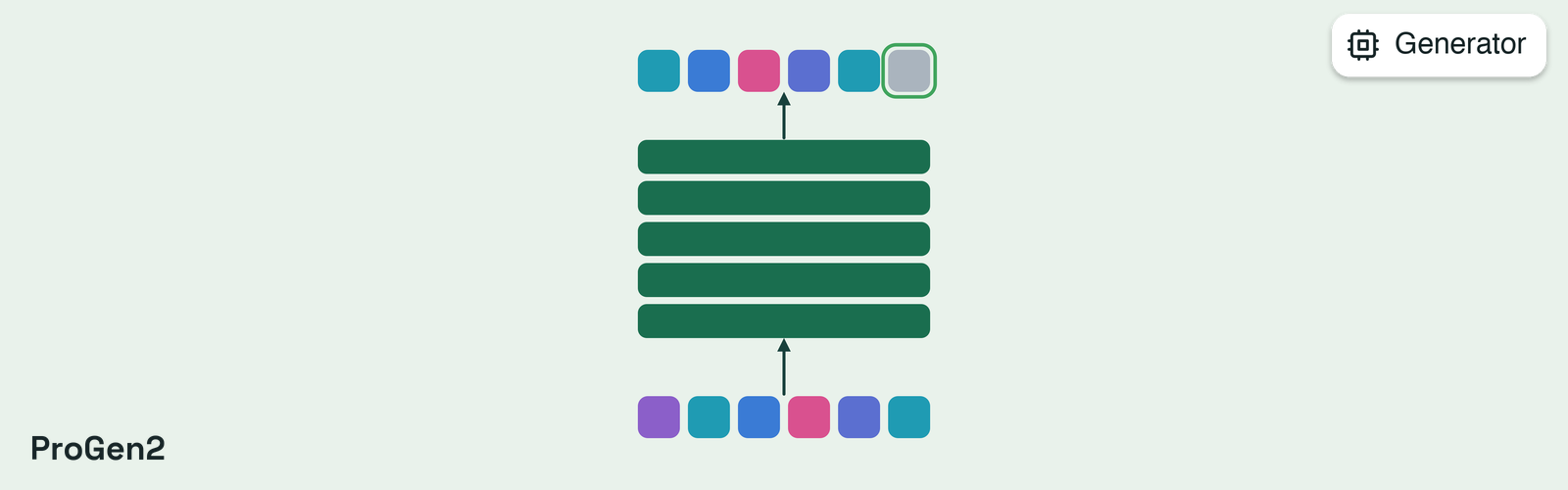
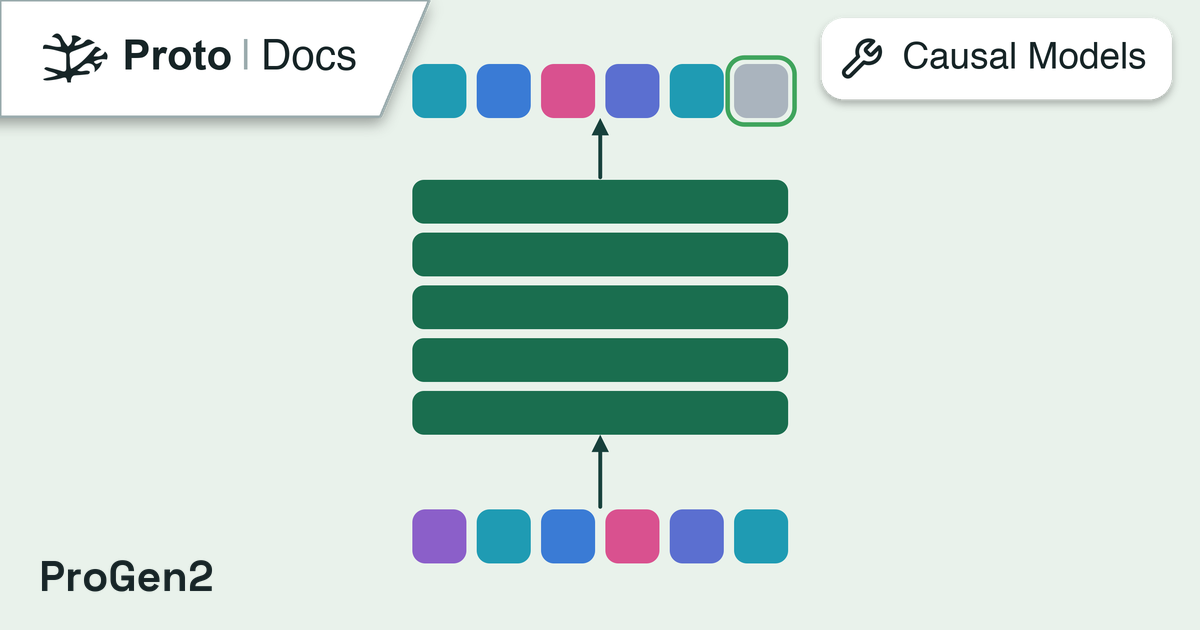
Configuration object for ProGen2Generator.This class defines configuration parameters for the ProGen2 generator, which uses
the ProGen2 protein language model to autoregressively generate protein sequences
from prompt sequences.Models are loaded from HuggingFace: https://huggingface.co/hugohrban/
For detailed information on ProGen2, see:
- HuggingFace: https://huggingface.co/hugohrban/
- GitHub: https://github.com/hugohrban/ProGen2-finetuning
- Original GitHub: https://github.com/enijkamp/progen2
- Original paper: https://www.cell.com/cell-systems/fulltext/S2405-4712(23)00272-7
Prompt sequences for protein sequence generation
ProGen2 model variant to load (e.g. progen2-large).Options:
progen2-small, progen2-medium, progen2-base, progen2-oas, progen2-large, progen2-BFD90, progen2-xlargePath to local model weights
GPU device to run ProGen2 on (e.g. ‘cuda’ or ‘cuda:0’).
Sharpness of sampling. Below 1 favors high-probability tokens; above 1 increases diversity.
Nucleus sampling cumulative probability cutoff. 1.0 disables nucleus sampling.
At each step, restrict sampling to the k most probable tokens. Set to 0 to disable top-k truncation.
Whether to truncate sequences at stop tokens
Whether to strip start and stop tokens from final output
Whether to prepend prompt to generation
Number of sequences to process simultaneously on GPU
Whether to print verbose output
Usage
python
Metadata
| Property | Value |
|---|---|
| Key | progen2 |
| Class | ProGen2Generator |
| Category | autoregressive |
| Input Type | prompt |
| Uses GPU | True |
| Supported Sequence Types | protein |
| Allows Empty Start | False |