License: This constraint can use multiple tools, each under its own license. See the Tools Used tab and each tool’s page for license details.
This constraint is open source. Any third-party models, product names, or trademarks referenced are the property of their respective owners, and Proto is not affiliated with them.
API Reference
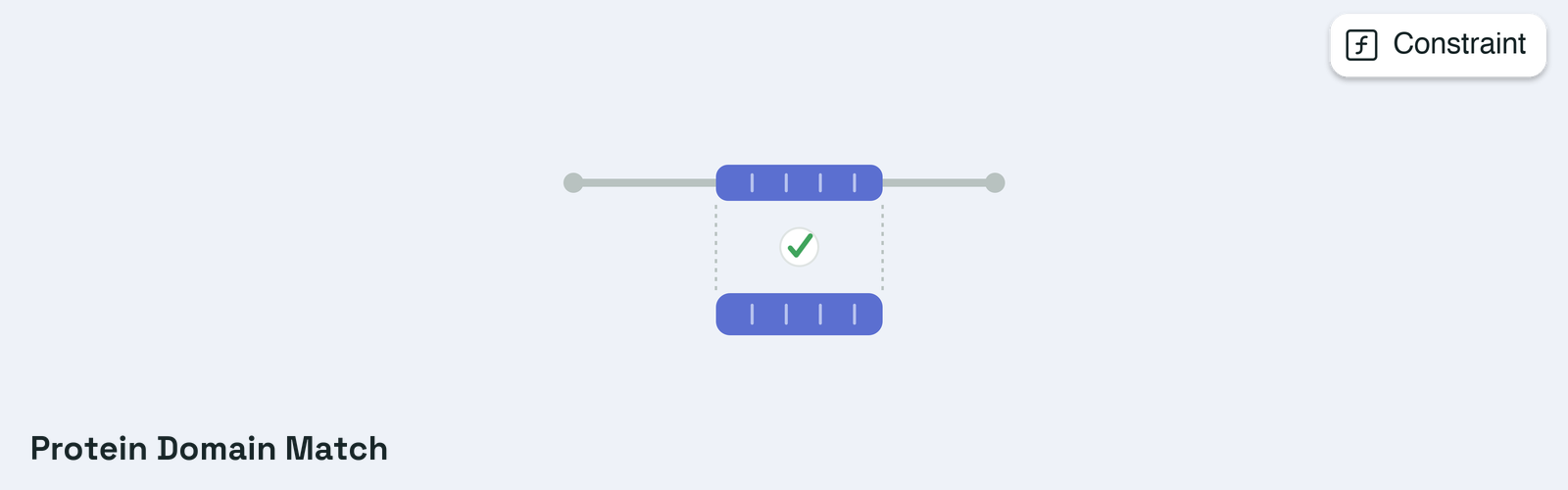
Configuration for protein domain constraint.This class defines configuration parameters for evaluating whether protein
sequences contain specific functional domains identified by keyword searches
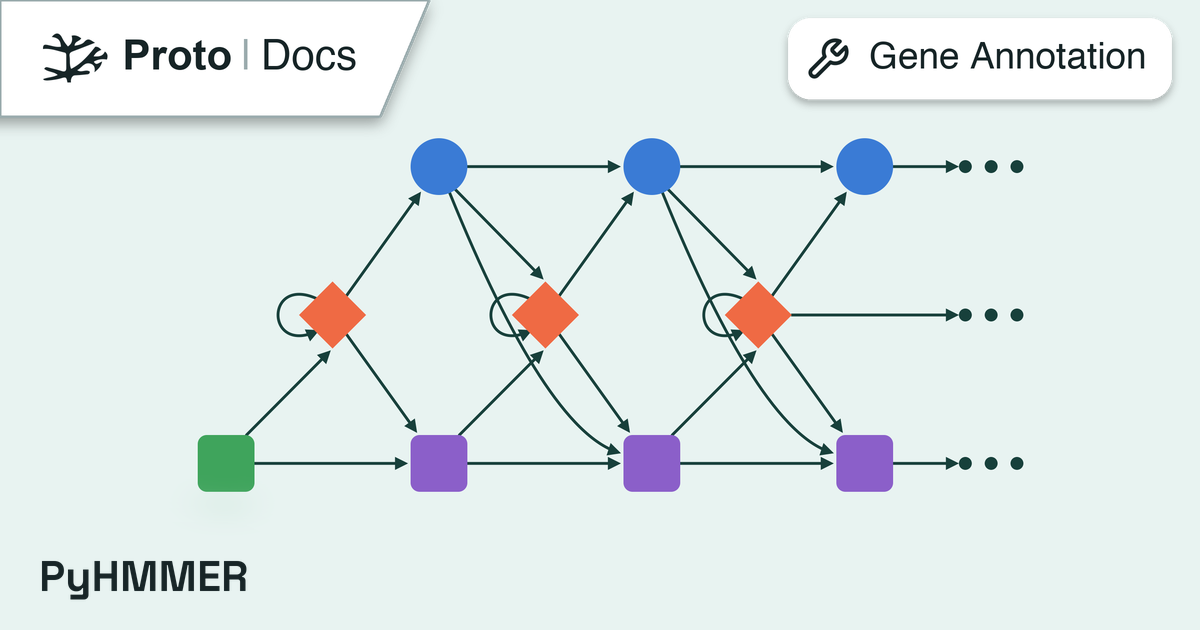
against HMM (Hidden Markov Model) profile databases. The constraint uses
HMMER’s hmmscan tool to identify protein domains and matches them against
user-specified keywords, enabling targeted selection for proteins with
desired functional characteristics.
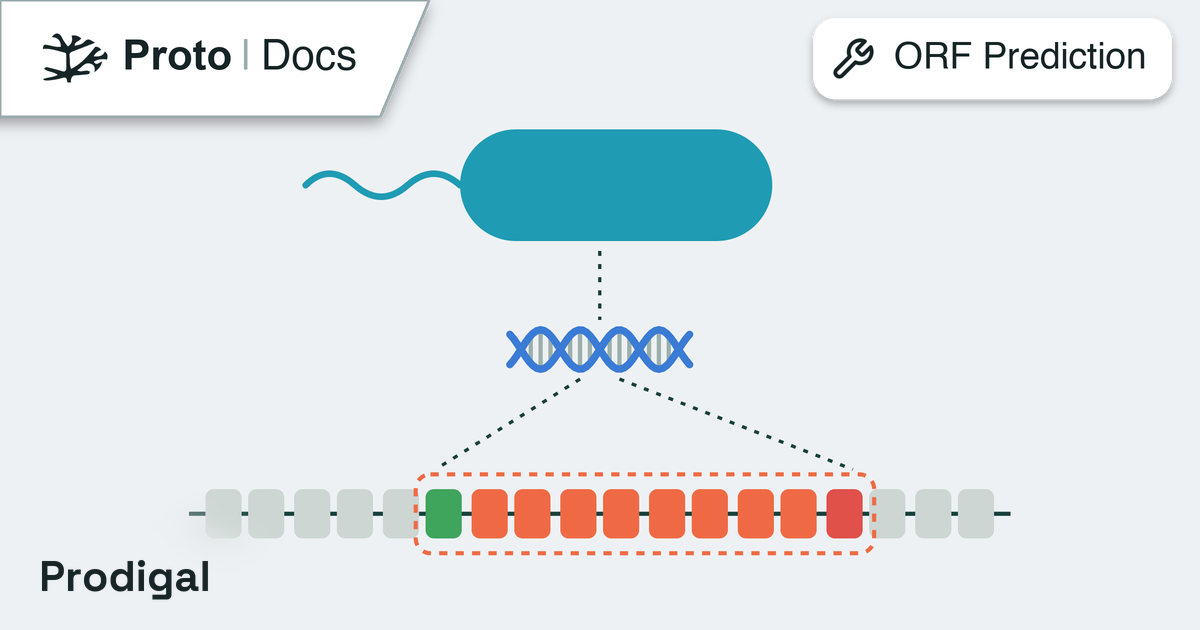
For DNA sequences, Prodigal is used to predict ORFs first, then each
predicted protein is searched for domains. For protein sequences, the
search is performed directly.
Path to HMM database file for hmmscan (e.g., Pfam-A.hmm). Must be pressed with hmmpress.
Keywords to search for in domain descriptions (case-insensitive).
Maximum E-value for significant HMM hits; lower is more stringent (typical range 0.0001 to 0.01).
Min query coverage percentage for significant hits (0-100).
If True, require ALL keywords to be found. If False, require ANY keyword (default).
Configuration for PyHMMER hmmscan.
ReturnsConstraintOutput
One result per sequence. A score of 0.0 indicates
domain criteria are satisfied (matching domains found) and 1.0 indicates
no matching domains found or failure to meet keyword requirements.
metadata carries:For DNA sequences:prodigal_proteins: List of dicts of predicted proteins from Prodigal (orNoneif no ORFs were predicted)prodigal_protein_count: Integer count of predicted ORFsdomain_search_results: List of domain search results for each predicted proteindomain_keywords_found: List of unique keywords found across all predicted proteinsdomain_matching_proteins: List of protein IDs that matched keywords
domain_search_results: List containing domain search resultsdomain_keywords_found: List of keywords found in domain descriptionsdomain_matching_hits: DataFrame of domain hits matching keywordshmmscan_all_hits: DataFrame of all significant hmmscan hits
Usage
Evaluating domain presence in protein with single keyword:python
python
Metadata
| Property | Value |
|---|---|
| Key | protein-domain |
| Function | protein_domain_constraint |
| Category | protein_quality |
| Mode | discrete |
| Uses GPU | False |
| Supported Types | dna, protein |