
License: This constraint can use multiple tools, each under its own license. See the Tools Used tab and each tool’s page for license details.
This constraint is open source. Any third-party models, product names, or trademarks referenced are the property of their respective owners, and Proto is not affiliated with them.

API Reference
Configuration for MMseqs gene similarity constraint.This class defines configuration parameters for evaluating sequence similarity
(percent identity) to known proteins using MMseqs2, an ultra-fast sequence
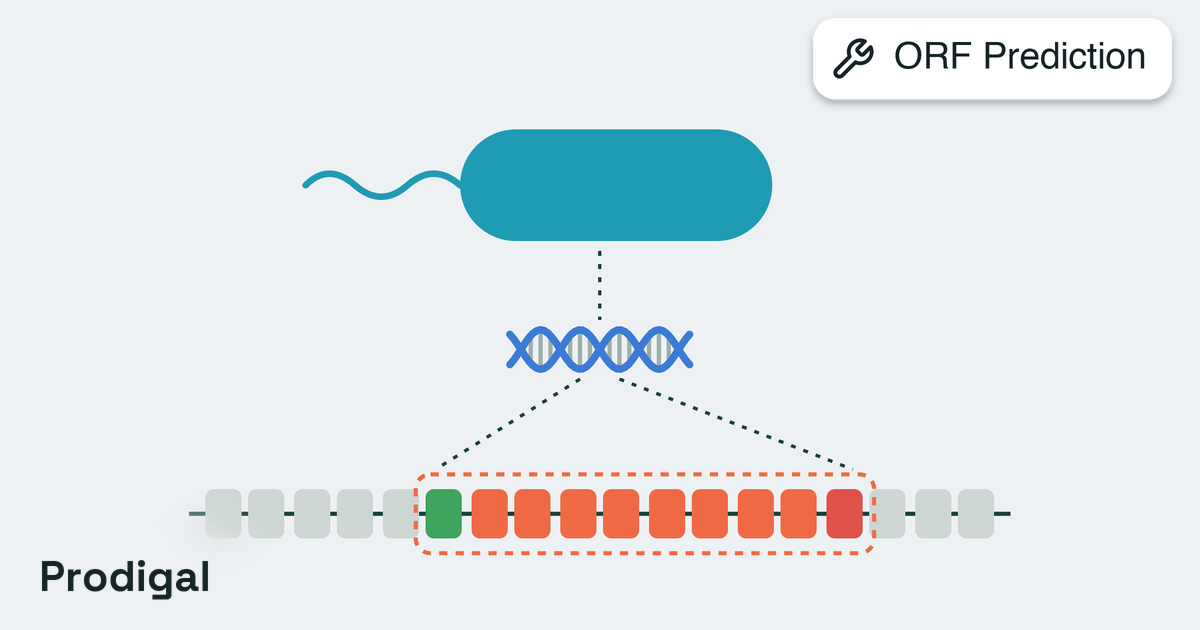
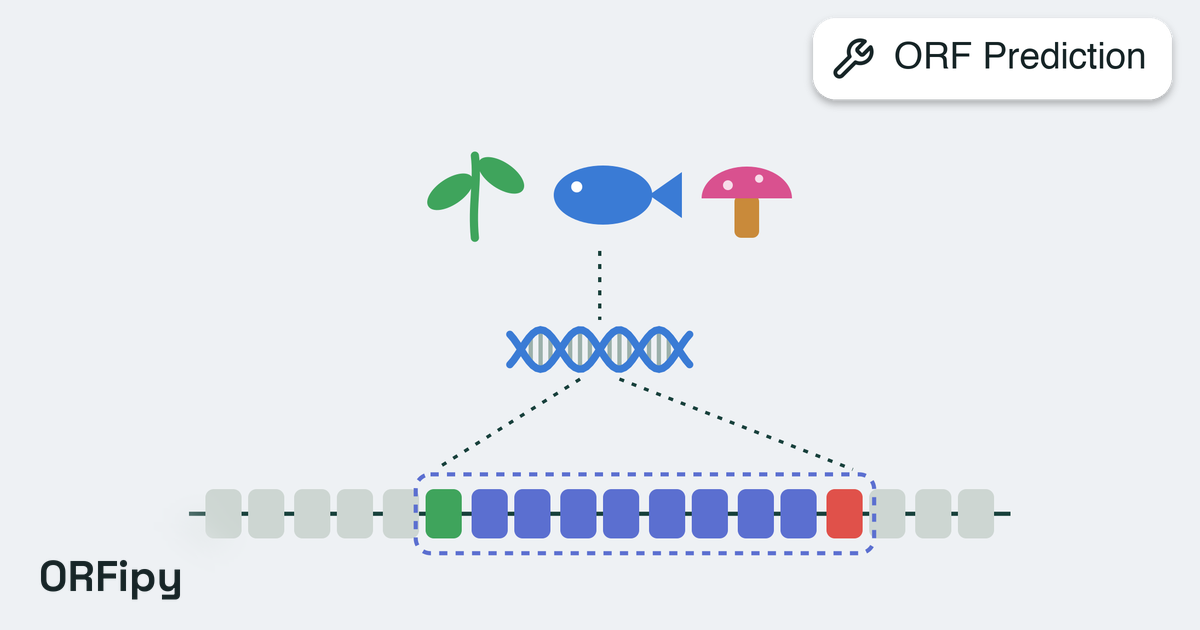
search tool. For DNA sequences, the constraint first predicts open reading
frames (ORFs) using either Prodigal or ORFipy, then searches the translated
proteins against a reference database. For protein sequences, the search is
performed directly.
For examples with tool configuration, see:
from proto_tools import Mmseqs2SearchProteinsConfig The similarity range [min_similarity, max_similarity] defines acceptable percent identity. Sequences with hits outside this range are penalized. For example:
- [40, 70]: Moderate similarity, useful for inferring functional similarity while avoiding identical sequences
- [0, 40]: Low similarity filter, for novelty/uniqueness constraints
- [80, 100]: High similarity filter, for functional conservation requirements
Minimum acceptable percent identity (0-100). Lower values are more permissive.
Maximum acceptable percent identity (0-100). Higher values allow more similar hits.
Path to MMseqs2 protein database for similarity search
MMseqs configuration (threads, sensitivity, etc.).
ORF prediction tool (DNA only): ‘orfipy’ (viral) or ‘prodigal’ (prokaryotic).Options:
orfipy, prodigalORFipy configuration (DNA only, used if orf_predictor=‘orfipy’).
Prodigal configuration (DNA only, used if orf_predictor=‘prodigal’).
ReturnsConstraintOutput
One result per sequence. Score 0.0 means all hits
fall within [min_similarity, max_similarity]; higher scores indicate
greater deviation. Score 1.0 (MAX_ENERGY) is returned if no ORFs are
found (DNA) or no database hits are found. metadata carries:For DNA sequences (with Prodigal):prodigal_orfs: List of dictionaries containing predicted ORF information (id, start, end, strand, protein_sequence, etc.)mmseqs_results: List of dictionaries with MMseqs2 hit information (target_id, pident, evalue)unique_orfs_with_hits: Integer count of distinct ORFs with at least one database matchorfs_with_acceptable_similarity: Integer count of ORFs with hits in acceptable rangetotal_orfs_with_hits: Integer total number of ORF-hit pairssimilarity_compliance_rate: Float fraction of hits within acceptable range (0.0-1.0)
orfipy_orfs: List of dictionaries with ORFipy ORF predictions- Other fields same as Prodigal above
direct_protein: Dictionary with protein information (id, sequence, length)mmseqs_results: List of MMseqs2 hit dictionariesunique_orfs_with_hits: Count of distinct ORFs with at least one hit (always 1 or 0 for a single protein, which has exactly one ORF)orfs_with_acceptable_similarity: Count of acceptable hitstotal_orfs_with_hits: Total hit countsimilarity_compliance_rate: Fraction of hits in range
Usage
Filtering for sequences with low similarity to existing proteins:python
Metadata
| Property | Value |
|---|---|
| Key | mmseqs-gene-similarity |
| Function | mmseqs_similarity_constraint |
| Category | sequence_annotation |
| Mode | discrete |
| Uses GPU | False |
| Supported Types | dna, protein |