- Input: a sequence to score, or a prompt to extend (DNA or protein).
- Output: newly generated sequences, or per-sequence likelihood and perplexity scores.
Causal Models
Causal Models
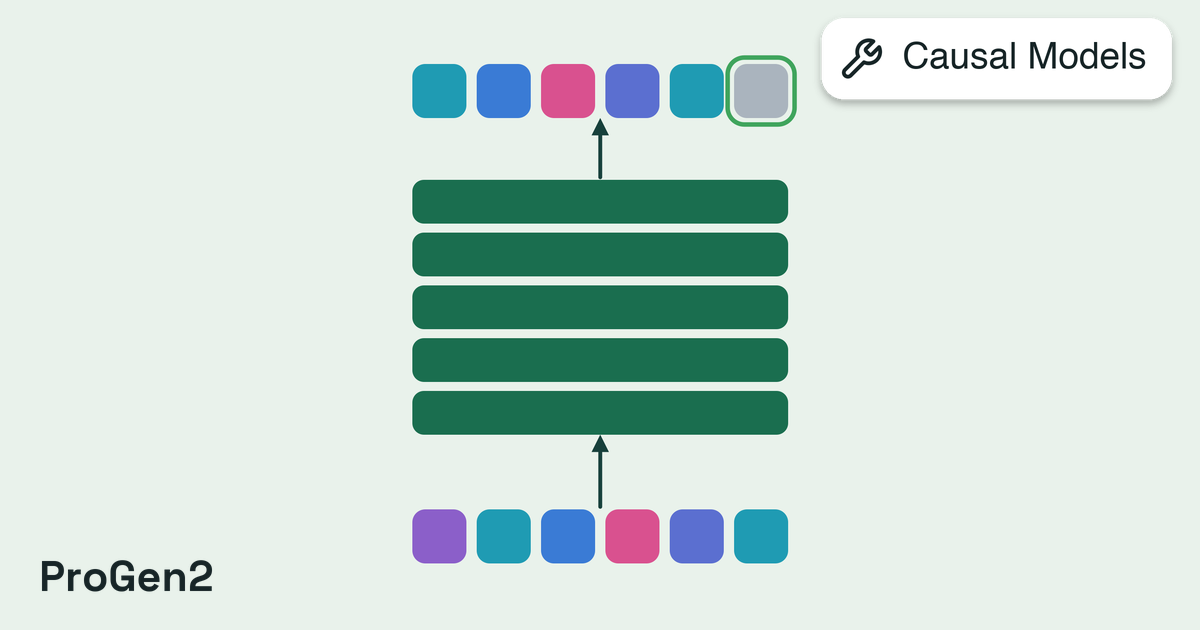
Autoregressive models for sequence generation and scoring
Autoregressive language models for biological sequences. Trained to predict the next residue
or nucleotide from the sequence so far, they generate new sequences one token at a time from
an optional prompt and score how likely an existing sequence is under the model. That
likelihood serves as a zero-shot proxy for how natural a sequence looks, across both DNA and
protein alphabets.

 Arc Institute
Arc Institute
 Salesforce Research
Salesforce Research
 Profluent
Profluent